燦都.水龍捲
Google Font Directory
本博換了標題字型,就是示範了 (Firefox 3.5 or above required)。Google Font Directory 可以讓一般網頁 embed 一些 open fonts,還設有即時預覽功能。可惜暫時只有英文字型。
喀麥隆的熨乳房酷刑
慎入。另見《華盛頓郵報》報道。
2010年7月23日星期五
2010年7月22日星期四
八爪 Paul 與未來哥番外篇:Bin(n,p) 的 95% C.I.

圖一:Clopper-Pearson(紅)及 The Suffocated(藍)的 95% C.I. 的覆蓋機率;此處 n=8
上一篇蒙
為二項式分佈找一個信賴區間,貌似簡單,其是統計學中一個著名難題。文獻中最早的構作方法,出現於 C.J. Clopper 及統計學家 E.S. Pearson 合著的一篇 1934 年文章[1]之中。其作法十分簡單:若觀察得到 X = x,那麼所需的 (1-α)×100% C.I.,就是一個區間 (a,b) ,其中端點 a 及 b 是等式
Pr(X ≤ x | p = a) = α/2 及 Pr(X ≥ x | p = b) = α/2的解。這種構作方式,與我於前篇提及,用 hypothesis testing 的角度去構作的方式,基本精神相同,只是我先前的做法在 X=n 的時候,考慮的是 one-sided test,而 Clopper-Pearson 考慮的,永遠都是 two-sided test。
讀者可能會想,是不是因為我從 one-sided test 出發,所以出事?確實有點關係,不過原因沒那麼單純。詳細情形容後再說,暫時且繼續談 Clopper-Pearson interval。
Clopper-Pearson interval 又通稱為 exact interval,原因是它保證有不少於 95% 的覆蓋機率 (coverage probability)。若你未聽過覆蓋機率這個詞語,就表示你念大學時很可能並非專攻統計學。且讓我們複習一下甚麼叫 95% C.I.。如果 X 是一個隨機變數,其分佈取決於參數 p,那麼一個 X 的 95% C.I. 是一個隨機區間 (a(X), b(X)),其端點 a(X), b(X) 為只取決於 X 而非 p 的函數,而且:
對任何固定的 p 而言,都有 Pr{ (a(X), b(X)) ∋ p } = 0.95。[2]舉個例,當我們說常態分佈 X~N(μ,σ2) 的 two-sided 95% C.I. 是 (X - 1.96σ, X + 1.96σ),意思就是 a(X) = X - 1.96σ,而 b(X) = X + 1.96σ。 要留意 X 是隨機變數,所以 (a(X), b(X)) 也是隨機的。當我們有了 (X - 1.96σ, X + 1.96σ) 這個 95% C.I.,我們可以觀察 X 的一個 outcome x,從而計算該 C.I. 的一個實現 (realization),而這個實現的區間 (x - 1.96σ, x + 1.96σ),也就是一般中學教科書所稱的 95% C.I.。實際上,這種懶惰的說法混淆了「隨機區間」跟「隨機區間的實現」兩者,不過下面我會依然從俗,不作區分。
Pr{ (a(X), b(X)) ∋ p } 的數值,就是隨機區間 (a(X), b(X)) 的所謂覆蓋機率,而所謂 95% C.I.,實際上就是一個覆蓋機率等於 0.95 的隨機區間。
在上面常態分佈的例子,不難驗證,不管 μ 的數值為何,Pr{ (X - 1.96σ, X + 1.96σ) ∋ μ } = Pr(μ - 1.96σ < X < μ + 1.96σ) = 0.95 這條等式都成立。然而,對許多隨機分佈,特別是離散分佈來說,覆蓋機率恰好等於 0.95 的隨機區間未必存在。不巧地,二項式分佈正是這樣的情形。這其實不難解釋。如果 X ~ Bin(n,p),而我們記 X = 0, 1, 2, ... n 的每一種情形的 likilihood function 為
fx(p) = C(n,x) px (1-p)n-x, x=0,1,...,n,而且將 (a(x), b(x)) 覆蓋 p 的真假值寫成 p 的 membership function:
δx(p) = 1 if a(x)< p < b(x), or 0 otherwise.那麼 (a(X), b(X)) 的 coverage probability 就是
Pr{ (a(X), b(X)) ∋ p } = f0(p) δ0(p) + f1(p) δ1(p) + ... + fn(p) δn(p).很明顯,每個 likelihood function fx(p) 都是連續函數:

圖二
然而,除非 (a(x), b(x)) = [0,1] 或者它是空集,否則 δn(p) 對 p 並不連續,因此覆蓋機率 Pr{ (a(X), b(X)) ∋ p } 亦非連續函數,更不可能等於 0.95 這個 constant (hence continuous) function。
舉例說,在八爪魚 Paul 的情形 (n=8),可以計算 Clopper-Pearson interval 如下:
[a(0), b(0)) = [0, 0.3694),
(a(1), b(1)) = (0.0032, 0.5265),
(a(2), b(2)) = (0.0319, 0.6509),
(a(3), b(3)) = (0.0852, 0.7551),
(a(4), b(4)) = (0.1570, 0.8430),
(a(5), b(5)) = (0.2449, 0.9148),
(a(6), b(6)) = (0.3491, 0.9681),
(a(7), b(7)) = (0.4735, 0.9968),
(a(8), b(8)] = (0.6306, 1.0000].
因此如圖三左所示,δ0(p) 是一個於 (0, 0.3694) 以內為 1,以外為 0 的階梯函數 (step function),而 f0(p) δ0(p) 則在 p=0.3694 處不連續(圖三右):

圖三:(左)f0(p), δ0(p) 及(右) f0(p) δ0(p)
對其他 fx(p) δx(p) 也有同樣情形:

圖四:fx(p) δx(p), x = 0,1,...,8.
所以覆蓋機率 f0(p) δ0(p) + f1(p) δ1(p) + ... + f8(p) δ8(p) 並不連續,更非恆等於 0.95:

圖五:Bin(8,p) 的 95% Clopper-Pearson interval 的 coverage probability
換句話說,雖然 Clopper-Pearson interval 俗稱為 "exact interval",但它一點也不 exact。事實上,在 n=8 的情形,它名義上為 95% 的 C.I. 實際上的覆蓋機率最少也差不多等於 0.97,超出 0.95 兩個百分點。
如果是連續分佈,它的覆蓋機率不是採取 f0(p) δ0(p) + f1(p) δ1(p) + ... + fn(p) δn(p) 這種有限和的形式,而是採取 ∫ fx(p) δx(p) dx 這種積分形式。因此,儘管每個 δx(p) 並不連續,但積分本身卻有機會連續,亦有機會可以設計成恆等於 0.95。
對離散分佈來說,往往不可能構作 exact C.I.,因此要退而求其次,但是放棄了覆蓋機率 = 0.95 這個目標之後,要換上一個甚麼目標,就要視乎情況。有些人希望保證覆蓋機率不少於0.95,Clopper-Pearson interval 則正正為此而設。
而我於前文所作嘗試,也是希望保證覆蓋機率不少於 0.95,可惜構作時卻犯了錯誤。這個做法將 x=n 的 95% C.I. 定為 (a,1],其中 a 為 Pr(X ≤ x | p = a) = 0.05 的解。類似地,x=0 的 95% C.I. 被定為 [0,b),其中 b 為 Pr(X ≥ x | p = b) = 0.05 的解。
原則上,這種取單邊走向的構作方式並沒有錯,對某些 n 來說,這種做法有時也可以獲得覆蓋機率不少於 0.95,同時區間闊度又比 Clopper-Pearson interval 窄的 95% C.I.。例如當 n=1,用前文所述方式得到的 95% C.I. 為
X=0: [0, 0.95),
X=1: [0.05, 1],
而相應的 Clopper-Pearson 95% C.I. 為
X=0: [0, 0.975),
X=1: [0.025, 1],
所以 Clopper-Pearson interval 較差。然而我這種構作方式卻不能保證對任何 n 都有不少於 95% 的覆蓋機率。當 n=8,就正好出事:我對 X=8 所作的 C.I. 為 (0.6877,1],所以,依照同樣原理,對 X=0 的 C.I. 就是 [0, 1-0.6877) = [0, 0.3123)。因此,f0(p) δ0(p) 及 f8(p) δ8(p) 有如下圖所示:

圖六
當 p=0.6877,剛好有 f0(p) δ0(p) + f8(p) δ8(p) = 0。因此,若要覆蓋機率在 p=0.6877 的時候不小於 0.95,我們必須有 f1(p) δ1(p) + ... + f7(p) δ7(p) ≥ 0.95。然而,這是絕不可能的,因為即使 δ1(p), ..., δ7(p) 全部等於 1,f1(0.6877) + ... + f7(0.6877) 仍不及 0.95 這麼大!
雖然我於前文的構作錯誤,但這並不是說 Clopper-Pearson interval 是唯一保證覆蓋機率達到 95% 的構作方式。事實上,只要小心平衡各個 (a(x), b(x)) 的端點的先後次序及整體分佈,我們仍可獲得覆蓋機率不少於 0.95,同時區間闊度又比 Clopper-Pearson interval 窄的 95% C.I.。例如以下就是 the suffocated 用某種貪婪算法 (greedy algorithm),對 n=8 所構作的 95% C.I.:
X=0: [0, 0.3156),
X=1: (0.0063, 0.5001),
X=2: (0.0464, 0.6845),
X=3: (0.1111, 0.7108),
X=4: (0.1929, 0.8071),
X=5: (0.2892, 0.8889),
X=6: (0.3155, 0.9536),
X=7: (0.4999, 0.9937),
X=8: (0.6844, 1.0000].
圖一是這個 C.I. 及 Clopper-Pearson intervals 的覆蓋機率,讀者可見我作的 C.I. 的覆蓋機率,比 Clopper-Pearson intervals 的覆蓋機率更接近 0.95。我的 C.I. 的平均覆蓋機率 0.9741,也比Clopper-Pearson interval 的 0.9860 低。此外,我的 C.I. 除了在 X=2 及 X=6 時比 Clopper-Pearson intervals 略長,其餘的都比 Clopper-Pearson intervals 短。
所以,要構作比 Clopper-Pearson "exact" C.I. 更 exact 的 C.I.,是可能的。然而這需要非常小心的電腦計算,而 Clopper-Pearson interval 可貴的地方,在於它可以用簡單而且直觀的方法,就能保證獲得覆蓋機率不小於名義信賴度的 C.I.。
鳴謝:多謝
註:
[1] C.J. Clopper and E.S. Pearson (1934), The use of confidence or fiducial limits illustrated in the case of the binomial. Biometrika, 26(4): 404-413.
[2] 寫成 (a(X), b(X)) ∋ p 而不是 p ∈ (a(X), b(X)),是為了強調有關的事件為「隨機區間 (a,b) 覆蓋固定的點 p」,而非「隨機的 p 落在固定區間 (a,b) 當中」。)
Label(s):
不學無術

小說
想起來,除了家中那本《托爾斯泰中短篇小說選》我會不時翻一下之外,其他看過的短篇小說,能記得起的就只有三篇了。一篇是 Jorge Luis Borges 的 The Garden of Forking Paths ,這還要是因為電視劇 FlashForward 提起,我才有興緻找來讀的呢!
其餘兩篇,是 Gabriel Garcia Marquez 收錄在 Strange Pilgrims 內的兩個短篇 I only came to use the phone 及 Sleeping beauty and the airplane。讀它們,已是 N 年前的事了。
此外,再努力回想,也記不起還看過甚麼,由此可見我如何「讀得書少」,不過本博寥寥可數的讀者之中,大概無人是因為文學的緣故到訪的吧。既然前文提到 Roald Dahl 的 Pig,而本博又極少談文藝,所以不妨在此略盡綿力推薦一下。
其餘兩篇,是 Gabriel Garcia Marquez 收錄在 Strange Pilgrims 內的兩個短篇 I only came to use the phone 及 Sleeping beauty and the airplane。讀它們,已是 N 年前的事了。
此外,再努力回想,也記不起還看過甚麼,由此可見我如何「讀得書少」,不過本博寥寥可數的讀者之中,大概無人是因為文學的緣故到訪的吧。既然前文提到 Roald Dahl 的 Pig,而本博又極少談文藝,所以不妨在此略盡綿力推薦一下。
2010年7月21日星期三
童話
從前有個小孩,幼承庭訓,性格溫厚善良,不愛殺生,素食廚藝亦高。有次發生意外,他父母俱亡。本來小孩可以承受一筆豐厚遺產,可是最後卻遭雙親一向信任的律師騙去所有金錢。然而小孩並無懷恨在心,仍積極地過每一個貧窮的日子。最近聽朋友提起,他的姪女在外國上中學,程度相當於本地的中四。在語文課老師開列的閱讀清單之中,包括了上述的兒童故事。然而他不記得該故事的作者,只記得她是上世紀六、七十年代中成名的女性主義作家。如有任何人知道該作者的名字,煩請告之。當然,上述故事經二手轉述,情節應與實際的總有多少出入。
一日,小孩無意中吃了一口美味的食物,追究之下才知道那是肉類,從此,小孩就很希望知道如何製作這樣的美食。終於有一日,小孩獲得一個機會,參觀製造該食品的工廠。他的希望終於實現了,不過他也很快發現,原來工廠所用的材料,就是各位參觀者。
他之所以知道這個事實,是因為現在剛好輪到他遭處理,只見刀子將他開膛切腹,製成食品。
2010年7月19日星期一
Fred Rogers
轉載自 xkcd.com:
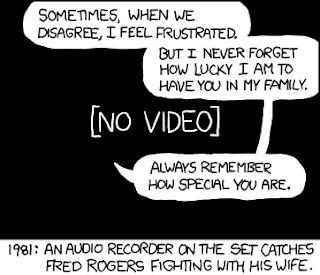
這 … 真的近乎聖人了。
上維基百科,查一查 Fred Rogers 是何許人,發現當錄影機剛剛面世,電視企業曾經企圖以訴訟方式管制錄影機的使用方法及收費制度,而 Fred Rogers 身為教育家及電視節目 "Neighborhood" 的製作人,卻贊成一般家庭自由錄影。他於最高法院所作供詞,亦被法官收錄入判詞之內:

這 … 真的近乎聖人了。
上維基百科,查一查 Fred Rogers 是何許人,發現當錄影機剛剛面世,電視企業曾經企圖以訴訟方式管制錄影機的使用方法及收費制度,而 Fred Rogers 身為教育家及電視節目 "Neighborhood" 的製作人,卻贊成一般家庭自由錄影。他於最高法院所作供詞,亦被法官收錄入判詞之內:
Some public stations, as well as commercial stations, program the "Neighborhood" at hours when some children cannot use it ... I have always felt that with the advent of all of this new technology that allows people to tape the "Neighborhood" off-the-air, and I'm speaking for the "Neighborhood" because that's what I produce, that they then become much more active in the programming of their family's television life. Very frankly, I am opposed to people being programmed by others. My whole approach in broadcasting has always been "You are an important person just the way you are. You can make healthy decisions." Maybe I'm going on too long, but I just feel that anything that allows a person to be more active in the control of his or her life, in a healthy way, is important.
2010年7月16日星期五
八爪 Paul 與未來哥 (II)
將八爪魚 Paul 猜中一場世界盃比賽賽果的機會率記為 p。現在 Paul 八測八中,如果我們因而推論 p=1,那麼當 Paul 只是七測七中又如何?再換成六測六中,或五測五中呢?在最極端的情況,如果 Paul 只預測了一次,而又估中賽果,那麼我們是否依然認為 p=1?
MLE 是很好的工具,但它有其局限。我們不能因為 Paul 八測八中而推論 Paul 永遠不會估錯,這應該是常識。然而現今的學校,不少都只實行填鴨式教育,以致學生只懂得一頭裁進公式的深海,反而忽略了顯而易見的道理。以 Paul 的例子來說,八測八中,百測百中跟一測一中,p 的 MLE 都是 1,但很明顯的,在這三種不同情況底下,任何人對 Paul 的預測能力的信心,都會有很大分別。單純對 p 的數值作出估計是不夠的,我們還需要一個可以因應比賽的總場數而調整闊窄的 p 的範圍。簡單來說,我們需要的就是一個信賴區間 (confidence interval)。
然而,如本文的前篇所述,若使用一般教科書所載的 Normal approximation 去計算 p 的 C.I.,結果仍舊只得 p=1 一點,而非一個長度大於零的區間。既然公式不管用,這時候,我們就唯有老老實實地用更基礎的方法找出 p 的 C.I.。
這其實並不太困難。C.I. 跟 hypothesis testing 是一體兩面,我們現在從後者的角度去看八爪魚 Paul 的預測。
Paul 的每場預測結果為 Bernoulli(p) 隨機變數,所以 n 場之後猜中的總數 X 循 Binomial(n,p) 分佈。現在 Paul 八測八中,無論是 MLE 抑或 unbiased estimate,p 的 point estimate 都是 1。現在我們問:如果我們認為 p 的真正數值 p0 沒有 1 那麼大,那我們可否用 5% 的顯著度去否定 H0: p≤ p0 這個命題?
由於 Pr(X≥n | p=p0) = p0n,因此只有當 p0 ≤ 0.05(1/n) ,我們才可以用 5% 的顯著度去否定 H0。換句話說,當我們觀察得 X=n,p 的 95% C.I. 應該是 (0.05(1/n), 1]。代入阿 Paul 的 n=8,得出 C.I. = (0.6877,1]。(後記:此處有錯,詳見番外篇。)
本來打鐵要趁熱,不過近來事忙,寫不了那麼多。下篇再續。
MLE 是很好的工具,但它有其局限。我們不能因為 Paul 八測八中而推論 Paul 永遠不會估錯,這應該是常識。然而現今的學校,不少都只實行填鴨式教育,以致學生只懂得一頭裁進公式的深海,反而忽略了顯而易見的道理。以 Paul 的例子來說,八測八中,百測百中跟一測一中,p 的 MLE 都是 1,但很明顯的,在這三種不同情況底下,任何人對 Paul 的預測能力的信心,都會有很大分別。單純對 p 的數值作出估計是不夠的,我們還需要一個可以因應比賽的總場數而調整闊窄的 p 的範圍。簡單來說,我們需要的就是一個信賴區間 (confidence interval)。
然而,如本文的前篇所述,若使用一般教科書所載的 Normal approximation 去計算 p 的 C.I.,結果仍舊只得 p=1 一點,而非一個長度大於零的區間。既然公式不管用,這時候,我們就唯有老老實實地用更基礎的方法找出 p 的 C.I.。
這其實並不太困難。C.I. 跟 hypothesis testing 是一體兩面,我們現在從後者的角度去看八爪魚 Paul 的預測。
Paul 的每場預測結果為 Bernoulli(p) 隨機變數,所以 n 場之後猜中的總數 X 循 Binomial(n,p) 分佈。現在 Paul 八測八中,無論是 MLE 抑或 unbiased estimate,p 的 point estimate 都是 1。現在我們問:如果我們認為 p 的真正數值 p0 沒有 1 那麼大,那我們可否用 5% 的顯著度去否定 H0: p≤ p0 這個命題?
由於 Pr(X≥n | p=p0) = p0n,因此只有當 p0 ≤ 0.05(1/n) ,我們才可以用 5% 的顯著度去否定 H0。換句話說,當我們觀察得 X=n,p 的 95% C.I. 應該是 (0.05(1/n), 1]。代入阿 Paul 的 n=8,得出 C.I. = (0.6877,1]。(後記:此處有錯,詳見番外篇。)
本來打鐵要趁熱,不過近來事忙,寫不了那麼多。下篇再續。
Label(s):
不學無術
2010年7月13日星期二
八爪 Paul 與未來哥 (I)
昨天正在想要不要吹水講下未來哥,見電鋸正好發新文講 Paul the Octopus,於是決定加把嘴。
用統計學來分析未來哥或者八爪魚 Paul 是神燈抑或神棍,嚴格來說是行不通的。整個統計推論 (statistical inference) 的基礎,是要有可以視為條件相同的重複實驗。然而世界盃每場的條件都不同,就算將來某一日 FIFA 改制,西班牙跟荷蘭的決賽要鬥 99 場,但是每場雙方的陣容與部署都可能不同,球員狀態、場地天氣等等因素更不在話下。當八爪魚 Paul 八測八中,實際上並非重複了八次同樣的實驗結果,而是做了八個完全不同的實驗。這八場賽事當中,雙方有時實力懸殊,有時旗鼓相當,故此預測的難度亦有別。將各場賽事視為 i.i.d. (identically and independently distributed) 的隨機變數,並不妥當。
話雖如此,利用這個 i.i.d. 的假設,也可以看出一些端倪。
電視台的新聞報道,一般都用擲銀幣的模型去看八爪魚 Paul 的預測,也就是如果 Paul 是亂猜,或猜中的機會率是 p=1/2,那麼八測八中的機會率,是 p 的八次方,亦即 1/256 = 0.39%。由於這個機會率實在太細,所以 Paul 的表現,肯定比亂猜要好。
撇除 i.i.d. 這個隱藏假設不說,若要說「八爪魚 Paul 的預測並非亂猜」,那麼眼前的証據還算有說服力,然而,若我們要考究的是八爪魚 Paul 的預測能力有多高,那前述的分析就不管用了,因為我們想估計的是 p 有多高,而不是 "p>1/2" 這個命題。就算是常人,估波估中的機會率,相信一般都略高於 1/2,所以純粹說 "p>1/2",也沒甚麼了不起。
要從猜中結果的世界盃場次數目推斷 p,貌似簡單,但實際上陷阱處處,正好作為大一統計課的範例。
於 i.i.d. 的假設之下,一般學生都會直覺地運用 maximum likelihood estimation (MLE)。由於每場預測都是一個 Bernoulli(p) 的實驗,因此 n 場賽事之中猜中 X 場(為求簡單,不妨假設分組賽不會打和),p 的 MLE 就是 X/n。對八爪魚 Paul 來說,X=n=8,因此 p=1。
此時, 若是不求甚解的學生,大概就會接納 p=1 這個結論。然而 Bernoulli(p) 是離散 (discrete) 而非連續 (continuous) 的隨機變數。若是連續分佈,即使對某個事件 E 來說有 Pr(E)=1,"not E" 這個事件還是有可能的(儘管機會率為零),但換了是有限的離散分佈,機會率為零的事件是絕不可能發生的。因此,若八爪魚 Paul 猜中的機會率為 1,那等於說 Paul 永遠都不會猜錯。這顯然不妥。
心思較細密的學生,可能會想起 p=1 只是一個 point estimate。由於 point estimate 不考慮統計誤差,因此較佳的做法是用 interval estimate,也就是與其說 p 是幾多,不如說 p 落在某個信賴區間 (confidence interval, C.I.) 之內。時下世界各地的大學都有教育經費問題,因此一般教科書都只是「淺入淺出」,凡是講 MLE 的 confidence interval,都是一招了,只講漸近常態分佈 (asymptotic normal approximation),還直接印出幾個常用統計分佈的 MLE 的 asymptotic variance 就算,對它們是怎樣計算出來 (亦即 Fisher information matrix 的概念) 隻字不提,幸而對 Bernoulli 分佈來說,p 的 MLE 的漸近常態分佈問題可以化為 Binomial distribution 的漸近分佈問題,是一般大一(甚至我念中學時的中學預科)都有教的簡單例子。總括來說,p 的 MLE 是 p0 = X/n,而 X/n 又漸近於 N(p; p(1-p)/n),因此若從觀察所得的猜中率為 p0 = x/n,那麼 p 的 95% C.I. 為
然而此處又舐野。由於 MLE p0 =1,所以其二次方差 (variance) p0(1-p0)/n = 0,亦即是說,point estimate 跟 interval estimate 根本無分別,兩者結果都是 1,認真大鑊。你話點搞?
吹吹下又寫了咁多,下篇再續。
用統計學來分析未來哥或者八爪魚 Paul 是神燈抑或神棍,嚴格來說是行不通的。整個統計推論 (statistical inference) 的基礎,是要有可以視為條件相同的重複實驗。然而世界盃每場的條件都不同,就算將來某一日 FIFA 改制,西班牙跟荷蘭的決賽要鬥 99 場,但是每場雙方的陣容與部署都可能不同,球員狀態、場地天氣等等因素更不在話下。當八爪魚 Paul 八測八中,實際上並非重複了八次同樣的實驗結果,而是做了八個完全不同的實驗。這八場賽事當中,雙方有時實力懸殊,有時旗鼓相當,故此預測的難度亦有別。將各場賽事視為 i.i.d. (identically and independently distributed) 的隨機變數,並不妥當。
話雖如此,利用這個 i.i.d. 的假設,也可以看出一些端倪。
電視台的新聞報道,一般都用擲銀幣的模型去看八爪魚 Paul 的預測,也就是如果 Paul 是亂猜,或猜中的機會率是 p=1/2,那麼八測八中的機會率,是 p 的八次方,亦即 1/256 = 0.39%。由於這個機會率實在太細,所以 Paul 的表現,肯定比亂猜要好。
撇除 i.i.d. 這個隱藏假設不說,若要說「八爪魚 Paul 的預測並非亂猜」,那麼眼前的証據還算有說服力,然而,若我們要考究的是八爪魚 Paul 的預測能力有多高,那前述的分析就不管用了,因為我們想估計的是 p 有多高,而不是 "p>1/2" 這個命題。就算是常人,估波估中的機會率,相信一般都略高於 1/2,所以純粹說 "p>1/2",也沒甚麼了不起。
要從猜中結果的世界盃場次數目推斷 p,貌似簡單,但實際上陷阱處處,正好作為大一統計課的範例。
於 i.i.d. 的假設之下,一般學生都會直覺地運用 maximum likelihood estimation (MLE)。由於每場預測都是一個 Bernoulli(p) 的實驗,因此 n 場賽事之中猜中 X 場(為求簡單,不妨假設分組賽不會打和),p 的 MLE 就是 X/n。對八爪魚 Paul 來說,X=n=8,因此 p=1。
此時, 若是不求甚解的學生,大概就會接納 p=1 這個結論。然而 Bernoulli(p) 是離散 (discrete) 而非連續 (continuous) 的隨機變數。若是連續分佈,即使對某個事件 E 來說有 Pr(E)=1,"not E" 這個事件還是有可能的(儘管機會率為零),但換了是有限的離散分佈,機會率為零的事件是絕不可能發生的。因此,若八爪魚 Paul 猜中的機會率為 1,那等於說 Paul 永遠都不會猜錯。這顯然不妥。
心思較細密的學生,可能會想起 p=1 只是一個 point estimate。由於 point estimate 不考慮統計誤差,因此較佳的做法是用 interval estimate,也就是與其說 p 是幾多,不如說 p 落在某個信賴區間 (confidence interval, C.I.) 之內。時下世界各地的大學都有教育經費問題,因此一般教科書都只是「淺入淺出」,凡是講 MLE 的 confidence interval,都是一招了,只講漸近常態分佈 (asymptotic normal approximation),還直接印出幾個常用統計分佈的 MLE 的 asymptotic variance 就算,對它們是怎樣計算出來 (亦即 Fisher information matrix 的概念) 隻字不提,幸而對 Bernoulli 分佈來說,p 的 MLE 的漸近常態分佈問題可以化為 Binomial distribution 的漸近分佈問題,是一般大一(甚至我念中學時的中學預科)都有教的簡單例子。總括來說,p 的 MLE 是 p0 = X/n,而 X/n 又漸近於 N(p; p(1-p)/n),因此若從觀察所得的猜中率為 p0 = x/n,那麼 p 的 95% C.I. 為
(p0 - 1.96 sqrt(p0(1-p0)/n), p0 - 1.96 sqrt(p0(1-p0)/n))。
然而此處又舐野。由於 MLE p0 =1,所以其二次方差 (variance) p0(1-p0)/n = 0,亦即是說,point estimate 跟 interval estimate 根本無分別,兩者結果都是 1,認真大鑊。你話點搞?
吹吹下又寫了咁多,下篇再續。
Label(s):
不學無術
2010年7月3日星期六
人貼我又貼
永遠爪哇
Hmm, 我是覺得好好笑的,不過大概要寫電腦程式的朋友才明白箇中笑點。片段最後有少量成人情節,未成年者慎入。
海闊天空
從《一個人在途上》blog 看到,上載到 YouTube 不過幾日。片中的 a cappella 予人清新感覺,不過我更欣賞攝影者能將香港的古蹟(相信是將軍澳茅湖仔廢堡)拍得這般優美。
Vivek Mahbubani
這個是從莫乃光的網誌看到。我覺得比起黃子華或張達明,Mahbubani 的表演雖然也算可觀,但終究是完全從自身經歷出發,吃光老本之後,才算真正考驗。
師奶劇《篤姫》
所謂大河劇,說穿了只是經過精美包裝的師奶劇,不過我得承認自己也很迷這套《篤姫》。亞視今次可謂捉到鹿也不識脫角,例如為篤姫配音的聲優,聲線予人中年婦的感覺,完全無少女味道;劇集又遭剪接得非常零碎,我找來網上老翻一看,估計亞視每集約莫剪去五分鐘片段。前述兩個缺點還算是非戰之罪,始終亞視阮囊羞澀,慳得就慳也是人之常情,它真正不可原諒的,是她將劇集原本的精美包裝變成醜陋的三不像。看過亞視版《篤姫》的讀者,只需觀看原裝的篤姫開場片段,就能夠明白亞視如何踐踏一件藝術品。
Hmm, 我是覺得好好笑的,不過大概要寫電腦程式的朋友才明白箇中笑點。片段最後有少量成人情節,未成年者慎入。
海闊天空
從《一個人在途上》blog 看到,上載到 YouTube 不過幾日。片中的 a cappella 予人清新感覺,不過我更欣賞攝影者能將香港的古蹟(相信是將軍澳茅湖仔廢堡)拍得這般優美。
Vivek Mahbubani
這個是從莫乃光的網誌看到。我覺得比起黃子華或張達明,Mahbubani 的表演雖然也算可觀,但終究是完全從自身經歷出發,吃光老本之後,才算真正考驗。
師奶劇《篤姫》
所謂大河劇,說穿了只是經過精美包裝的師奶劇,不過我得承認自己也很迷這套《篤姫》。亞視今次可謂捉到鹿也不識脫角,例如為篤姫配音的聲優,聲線予人中年婦的感覺,完全無少女味道;劇集又遭剪接得非常零碎,我找來網上老翻一看,估計亞視每集約莫剪去五分鐘片段。前述兩個缺點還算是非戰之罪,始終亞視阮囊羞澀,慳得就慳也是人之常情,它真正不可原諒的,是她將劇集原本的精美包裝變成醜陋的三不像。看過亞視版《篤姫》的讀者,只需觀看原裝的篤姫開場片段,就能夠明白亞視如何踐踏一件藝術品。
訂閱:
留言 (Atom)